



Leveraging Transfer Learning for Faster Model Development
Tired of slow AI training? 😩 Transfer learning is your shortcut! 🚀 Use pre-trained models to boost performance and speed, even with limited data. Learn how in this guide.


Let's be honest, the task of training a deep learning model from scratch may feel overwhelming.
You need tons of data, immense computational power, and, let's not forget, a generous dose of patience. But what if I told you there's a shortcut? A technique that lets you leverage the knowledge of pre-trained models to accelerate your own model development?
Enter transfer learning, your new secret weapon in the AI development arena. 😉
What is Transfer Learning and Why Should You Care? 🤔
Think of transfer learning as the art of teaching an old dog new tricks, but in the world of AI. It's a machine learning technique where a model trained on one task is repurposed for a second, related task. Instead of starting from square one, you leverage a pre-trained model as a starting point.

Why is this a game-changer?
Faster Development: Dramatically reduces training time, especially when dealing with limited data.
Improved Performance: Often leads to better model accuracy, particularly with smaller datasets.
Resource Efficiency: Requires less computational power and data compared to training from scratch.
Democratizes AI: Makes deep learning more accessible to those without access to massive datasets or high-end hardware.
Key Strategies for Applying Transfer Learning
Transfer learning isn't a one-size-fits-all solution. There are different ways to implement it, depending on your specific needs and resources. Here are the main approaches:
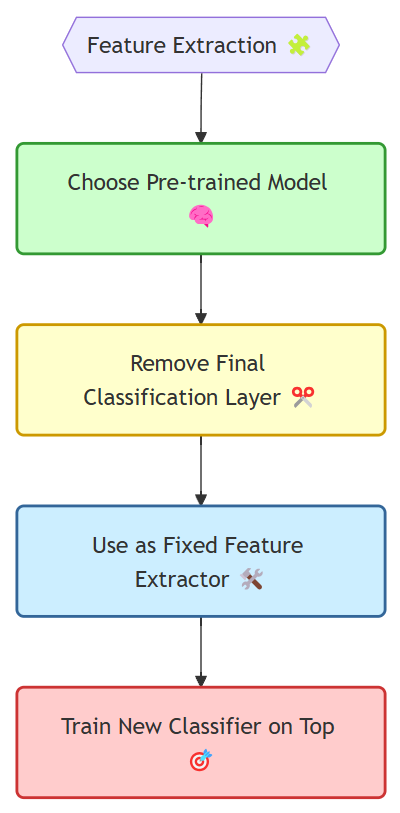
1. Feature Extraction: Using a Pre-trained Model as a Feature Extractor
This is the simplest and often most effective approach, especially when your new task is closely related to the original task the model was trained on.
How it works:
Take a Pre-trained Model: Choose a model that was trained on a large dataset and a task similar to yours. For example, if you're working with images, models like ResNet, VGG, or Inception, pre-trained on ImageNet, are great starting points.
Remove the Final Classification Layer: This is the layer that makes specific predictions for the original task. We don't need it for our new task.
Treat the Remaining Layers as a Fixed Feature Extractor: Feed your new dataset through these layers to get a set of features.
Train a New Classifier on Top: Add a new classification layer (or layers) and train it on the extracted features from your dataset.
Example:
Let's say you want to build a classifier that distinguishes between different types of flowers 🌸, but you only have a small dataset. You could use a model like ResNet, pre-trained on ImageNet (which contains images of various objects, including some flowers). You remove ResNet's final classification layer and use the remaining layers to extract features from your flower images. Then, you train a new classifier on these features to specifically recognize your flower types.
Common Mistakes to Avoid:
Choosing an Unrelated Pre-trained Model: If your task is significantly different from the original task, the extracted features might not be relevant.
Freezing Too Many Layers: While freezing the pre-trained layers is common, you might get better results by fine-tuning some of the later layers (more on this below).
Ignoring Data Preprocessing: Ensure your new data is preprocessed in the same way as the data the original model was trained on (e.g., image resizing, normalization).
Things to Watch Out For:
Feature Relevance: The features extracted by the pre-trained model should be relevant to your new task.
Computational Cost: While feature extraction is generally faster than training from scratch, it can still be computationally expensive for very large datasets.
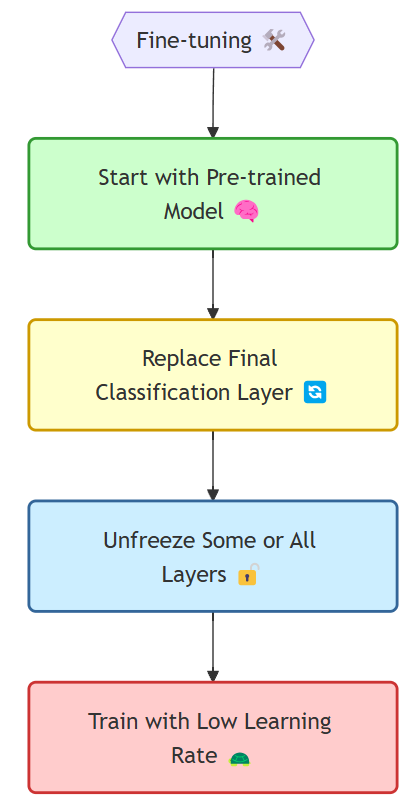
2. Fine-tuning: Adapting the Pre-trained Model to Your Specific Task
This approach involves not just using the pre-trained model as a feature extractor but also updating its weights during training on your new dataset. It's like giving the "old dog" a refresher course along with the new tricks.
How it works:
Start with a Pre-trained Model: Similar to feature extraction, choose a relevant pre-trained model.
Replace the Final Classification Layer: Swap it out for a new layer suitable for your task.
Unfreeze Some or All Layers: Decide which layers you want to fine-tune. You might start by unfreezing only the later layers and gradually unfreeze earlier layers as needed.
Train with a Low Learning Rate: Use a smaller learning rate than you would when training from scratch to avoid drastic changes to the pre-trained weights.
Example:
Suppose you want to build a model that detects defects in a specific type of manufactured product 🏭. You could start with a model trained on a general object detection task. You replace the final classification layer to output defect categories relevant to your product. Then, you unfreeze some of the later layers and train the entire model on your dataset of product images, using a low learning rate. This allows the model to adapt its learned features to the specific characteristics of your product's defects.
Common Mistakes to Avoid:
Using a High Learning Rate: This can destroy the valuable pre-trained weights. Stick to a learning rate that's 10x or even 100x smaller than what you'd use for training from scratch.
Unfreezing Too Many Layers Too Early: Start by unfreezing the later layers and gradually work your way back. Unfreezing too many layers initially can lead to instability.
Overfitting to the New Dataset: Even with a pre-trained model, you can still overfit if your dataset is too small. Use techniques like data augmentation and regularization (which we discuss below).
Things to Watch Out For:
Catastrophic Forgetting: When fine-tuning, the model might "forget" what it learned from the original task. This is more likely if the new task is very different from the original one.
Computational Cost: Fine-tuning is more computationally expensive than feature extraction, as you're updating the weights of a large model.
3. Domain Adaptation: Bridging the Gap Between Different Domains
This is a more advanced form of transfer learning used when your source data (where the pre-trained model comes from) and target data (your new dataset) have different distributions. For example, you might have a model trained on images of real-world objects, but you want to apply it to images of objects in a video game.
How it Works:
Uses techniques to align the feature representations of the source and target domains, making the pre-trained model more effective on the target data.
Might involve adversarial training or other specialized methods to minimize the "domain gap."
Example:
Imagine training a model to detect pedestrians in self-driving car data 🚗. You might have a large dataset of images from one city, but you want to deploy your model in a different city with different lighting, weather conditions, and even different types of pedestrians. Domain adaptation techniques can help bridge this gap.
Common Mistakes to Avoid:
Assuming Domains are Too Similar: If the domains are too different, standard transfer learning might not be sufficient.
Ignoring Domain-Specific Features: You might need to incorporate features that are specific to the target domain.
Things to Watch Out For:
Complexity: Domain adaptation can be significantly more complex than basic transfer learning.
Data Requirements: You still need a labeled dataset in the target domain, although it can be smaller than what would be required for training from scratch.
Advices and Tips: Mastering the Art of Transfer Learning
Choose the Right Pre-trained Model: This is crucial! ⚠️ Consider the original task, dataset, and architecture of the model.
Experiment with Different Approaches: Try both feature extraction and fine-tuning to see which works best for your task.
Use a Validation Set: Monitor performance on a separate validation set to tune hyperparameters and prevent overfitting.
Don't Forget Data Augmentation: Even with transfer learning, data augmentation can still improve performance, especially with smaller datasets.
Regularization: Apply techniques like L1/L2 regularization or dropout to prevent overfitting, especially when fine-tuning.
Be Mindful of Computational Resources: Fine-tuning can be resource-intensive. Consider your hardware limitations and optimize accordingly.
Layer Freezing Strategy: When fine-tuning, don't just randomly unfreeze layers. A common and effective strategy is to start by unfreezing the last few layers (closest to the output) and then gradually unfreeze earlier layers as needed. This allows the model to first adapt the higher-level, more task-specific features before adjusting the lower-level, more general features. Monitor the validation performance as you unfreeze more layers to find the optimal balance between adapting to the new task and retaining valuable pre-trained knowledge.
Transfer learning is a powerful tool that can significantly speed up your AI model development process, and you don't need to be a tech giant with unlimited resources to use it. By understanding these strategies and tips, you can leverage the power of pre-trained models to build better models faster, even with limited data. Go forth and transfer that knowledge! 🎉
❓Questions Deepdive:
1️⃣ How can we strategically determine the optimal number of layers to unfreeze during fine-tuning, balancing computational cost with the risk of catastrophic forgetting?
Start by unfreezing only the final classification layer and gradually unfreeze earlier layers one by one or in small groups.
Monitor performance on a validation set after each unfreezing step to identify the point of diminishing returns or performance degradation.
Consider the similarity between the original and target tasks: more dissimilar tasks may require unfreezing more layers for effective adaptation.
2️⃣ Beyond standard image datasets like ImageNet, what are some promising alternative sources of pre-trained models for specialized domains like medical imaging or industrial inspection?
Emerging repositories and research publications are increasingly offering models pre-trained on domain-specific datasets, such as medical scans (e.g., CheXNet) or industrial inspection images.
Organizations within specific industries are beginning to share pre-trained models, creating opportunities for collaboration and accelerated development within those fields.
Transfer learning can also be applied between related specialized domains, for example, using a model trained on satellite imagery for agricultural analysis.
3️⃣ How can adversarial training techniques be integrated into transfer learning to enhance the robustness and security of models, especially in sensitive applications like autonomous driving or medical diagnosis?
Adversarial training during fine-tuning can make models more resilient to adversarial examples in the target domain.
Techniques like domain-adversarial training can be used to create models that are invariant to domain shifts while remaining robust.
Integrating adversarial robustness measures from the outset can prevent costly retrofitting later.
4️⃣ What strategies can be employed to quantify and mitigate the "domain gap" when applying transfer learning between significantly different domains, such as from natural images to synthetic or artistic data?
Metrics like Maximum Mean Discrepancy (MMD) or Fréchet Inception Distance (FID) can quantify the difference between domain distributions.
Employing domain adaptation techniques like correlation alignment (CORAL) or adversarial methods can help minimize the measured domain gap.
Visualizing feature representations from both domains using techniques like t-SNE can provide qualitative insights into the domain gap.
5️⃣ In the context of federated learning, how can transfer learning principles be adapted to leverage pre-trained models across decentralized data sources without compromising data privacy?
Pre-trained models can be used as a starting point for federated learning, reducing the number of communication rounds needed for convergence.
Techniques like federated distillation can leverage knowledge from a central pre-trained model to improve the performance of local models without sharing raw data.
Differential privacy mechanisms can be incorporated to add an extra layer of privacy protection when fine-tuning pre-trained models in a federated setting.
6️⃣ How can the concept of "learning without forgetting" be incorporated into transfer learning to create models that can sequentially learn new tasks without degrading performance on previously learned ones?
Techniques like Elastic Weight Consolidation (EWC) or Synaptic Intelligence (SI) can be used to protect important weights learned from previous tasks during fine-tuning.
Rehearsal-based methods, where the model is periodically trained on a small subset of data from previous tasks, can also help mitigate catastrophic forgetting.
Developing architectures that can dynamically expand to accommodate new knowledge while preserving existing capabilities is an active area of research.
7️⃣ What role can meta-learning play in optimizing the transfer learning process, particularly in automating the selection of optimal pre-trained models and hyperparameters for a given target task?
Meta-learning algorithms can be trained to predict which pre-trained models and hyperparameters are likely to perform well on a new task, based on its characteristics.
Techniques like few-shot learning can enable rapid adaptation to new tasks with very limited data, by leveraging knowledge gained from a diverse range of previous tasks.
This could ultimately lead to a more automated and efficient transfer learning pipeline, where the system intelligently selects and adapts the best pre-trained models for any given problem.
8️⃣ How can we develop evaluation metrics that go beyond simple accuracy to assess the true effectiveness of transfer learning, considering factors like adaptation speed, data efficiency, and computational cost?
Metrics that measure the speed of convergence during fine-tuning can quantify the time-saving aspect of transfer learning.
Data efficiency can be evaluated by comparing the performance of a transferred model to one trained from scratch, given the same limited dataset.
Computational cost analysis should consider not just training time but also the resources required for model selection, adaptation, and inference.
A comprehensive evaluation framework should combine these factors to provide a more complete picture of transfer learning's practical effectiveness, beyond raw accuracy.